RCU 机制及 Userspace RCU 实现
1 RCU overview
RCU 的基本思想是将共享数据的更新 (update) 分为修改 (removal) 和回收 (reclamation) 两个部分, removal 阶段将数据拷贝一份并进行修改, 然后进入容忍期 (grace period) 等待所有在容忍期前的读者所在的 CPU 发生上下文切换, 然后进入 reclamation 阶段完成数据的更新回收
如下图所示, 每个读者在所在的 RCU read-side critical sections (蓝色矩形) 内不会 block (除了 sleepable rcu 或 preemptible rcu 等), 写者保证每个在 grace period 前开始执行的读者在 grace period 内完成:
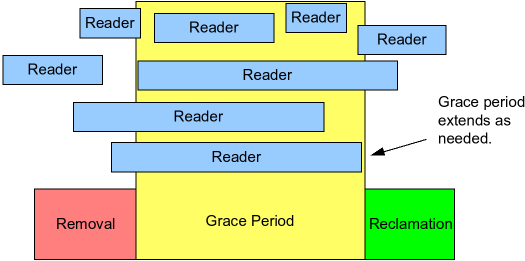
这样做的目的是将读者的开销减小写者的开销增加, 从而在读多写少的场景下相比于读写锁获得更好的性能, 下图为 RCU 和读写锁使用的趋势:
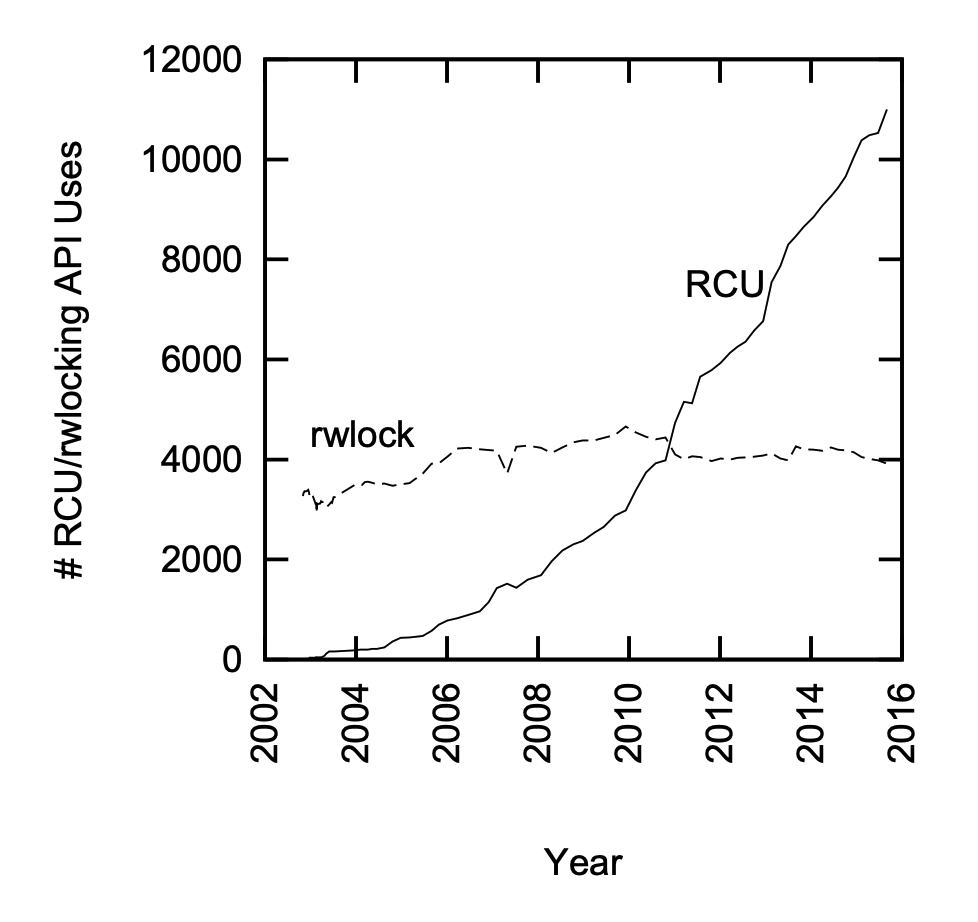
RCU 在 linux 内核中的所有锁定原语中的占比也逐年增长:
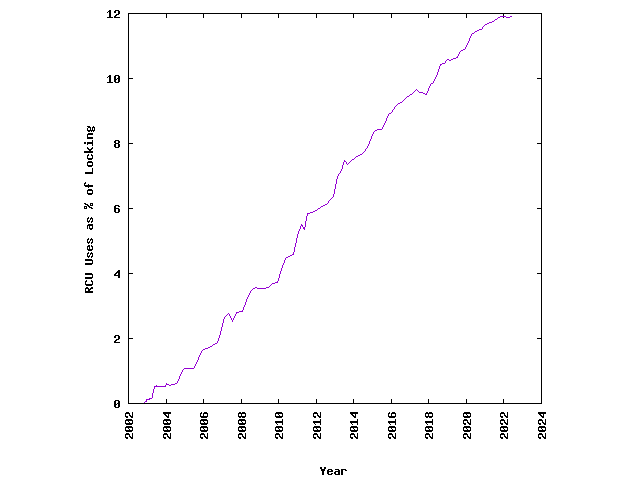
下表为 RCU 的使用: RCU primitives
| rcu_read_lock() / rcu_read_unlock() | 读者进入/退出 read-side critical section |
| rcu_assign_pointer() | 写者更新数据 |
| rcu_dereference() | 读者订阅数据 |
| synchronize_rcu() / call_rcu() | 写者同步/异步等待所有 CPU 对旧数据的使用完成 |
对比 Readers-writer lock 如 Reader-Writer Spin Locks 这种读者优先的锁, RCU 不会造成 writer starvation, 读者写者可以切换, 读者的开销少
同样适合于读多写少场景的 seqlock, 机制上存在不同, seqlock 在写过于频繁时读者可能一直需要循环更新值
do {
seq = read_seqbegin(&jiffies_lock);
ret = jiffies_64;
} while (read_seqretry(&jiffies_lock, seq));
2 Userspace RCU
2.1 内存屏障

userspace-rcu 中使用到了 3 种内存屏障:
2.1.1 编译级的屏障
编译级的屏障保证编译生成的汇编代码的顺序是按照程序文本的顺序, 但实际运行的时候 CPU 仍有可能将它们乱序 (out-of-order)
/* only compiler barrier */
#define barrier() __asm__ __volatile__ ("":::"memory")
2.1.2 CPU 级的屏障
CPU 级别的屏障保证实际执行的顺序是按照程序文本的顺序, 同时保证了多 CPU 间的缓存一致性
CPU 间的缓存一致性 (cache coherence) 是指被缓存在不同地方的数据保持资料一致性的机制, 由于 CPU 的速度往往比主存快得多, CPU 需要将数据缓存到自己的 L1 缓存中, 根据 MESI 协议将数据分为4种状态: 已修改 Modified (M), 独占 Exclusive (E), 共享 Shared (S), 无效 Invalid (I)
缓存一致性协议下的 CPU 缓存如图所示:
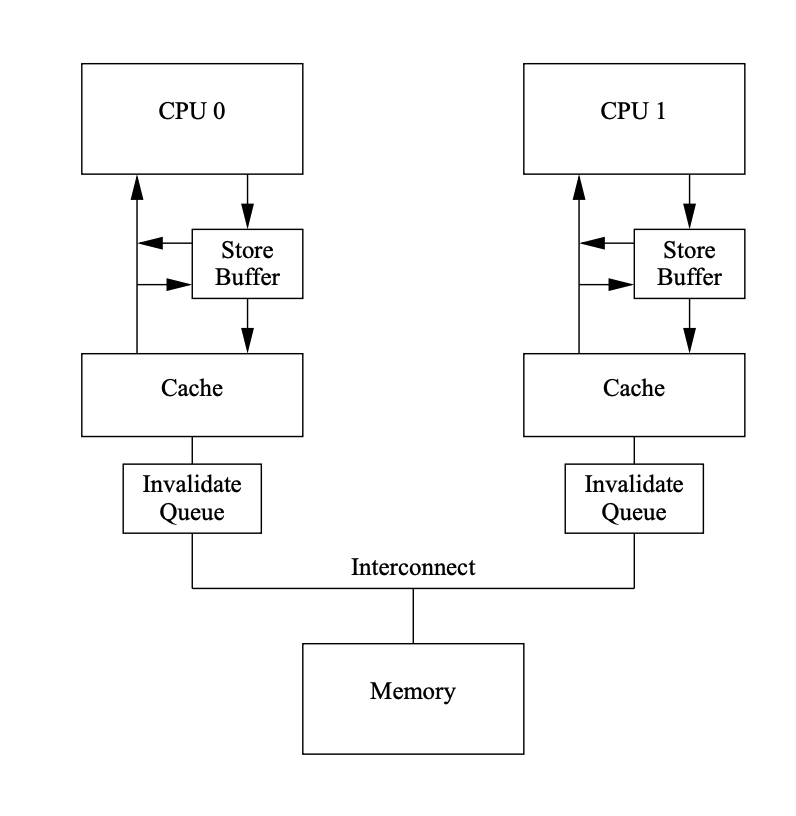
为了减少不必要的 stalls, 如图所示用到了 store buffer, store forwarding, invalidate queue
内存屏障可以控制 store buffer 和 invalidate queue, 如写屏障 load fence 会标记刷新 store buffer, 读屏障 store fence 会标记刷新 invalidate queue, 具体例子可见 Memory Barriers: a Hardware View for Software Hackers, Paul E. McKenney
x86 Total Store Order 下没有 store-store, load-store 和 load-load 乱序, 故我们只需要考虑 store-load 乱序, 如下面代码所示, fast_path 和 slow_path 都有对共享数据 a 和 b 的先存后取 (store-load), 如果缺少了两个内存屏障就有可能会存在 read_b 和 read_a 均等于0的情况
/* modified from https://man7.org/linux/man-pages/man2/membarrier.2.html */
#include <stdlib.h>
#include <pthread.h>
#include <stdio.h>
static volatile int a, b;
static void *fast_path(void *read_b)
{
a = 1;
asm volatile ("mfence" : : : "memory");
*(int *)read_b = b;
return NULL;
}
static void *slow_path(void *read_a)
{
b = 1;
asm volatile ("mfence" : : : "memory");
*(int *)read_a = a;
return NULL;
}
int main(int argc, char *argv[])
{
int read_a, read_b;
pthread_t slow_thread, fast_thread;
pthread_create(&slow_thread, NULL, slow_path, &read_a);
pthread_create(&fast_thread, NULL, fast_path, &read_b);
pthread_join(slow_thread, NULL);
pthread_join(fast_thread, NULL);
if (read_b == 0 && read_a == 0)
abort();
printf("read_a = %d, read_b = %d\n", read_a, read_b);
exit(EXIT_SUCCESS);
}
x86-TSO 下的 store-load barrier 的实现除了上述的 mfence 外, lock 前缀的命令也可以达到相同效果
/* x86-TSO store-load barrier */
#define smp_mb() __asm__ __volatile__ ("mfence":::"memory")
/* x86-TSO store-load barrier for that lacks mfence instruction */
#define smp_mb2() __asm__ __volatile__ ("lock; addl $0,0(%%rsp)":::"memory")
2.1.3 membarrier
membarrier 是减少 CPU 级别的内存屏障指令开销的一种屏障, 适用场景为, 有些用到了屏障的函数被执行的频率比另一些用到了屏障的函数高的多, 如下面代码中, 若 fast_path 被执行的频率远远高于 slow_path 被执行的频率, 那么使用一个编译级内存屏障加 membarrier 的组合可能会比使用两个 store-load 内存屏障的开销要小
/* modified from https://man7.org/linux/man-pages/man2/membarrier.2.html */
#include <stdlib.h>
#include <pthread.h>
#include <stdio.h>
#include <sys/syscall.h>
#include <linux/membarrier.h>
static volatile int a, b;
static int membarrier(int cmd, unsigned int flags, int cpu_id)
{
return syscall(__NR_membarrier, cmd, flags, cpu_id);
}
static void *fast_path(void *read_b)
{
a = 1;
asm volatile ("" : : : "memory");
*(int *)read_b = b;
return NULL;
}
static void *slow_path(void *read_a)
{
b = 1;
membarrier(MEMBARRIER_CMD_GLOBAL, 0, 0);
*(int *)read_a = a;
return NULL;
}
int main(int argc, char *argv[])
{
int read_a, read_b;
pthread_t slow_thread, fast_thread;
pthread_create(&slow_thread, NULL, slow_path, &read_a);
pthread_create(&fast_thread, NULL, fast_path, &read_b);
pthread_join(slow_thread, NULL);
pthread_join(fast_thread, NULL);
if (read_b == 0 && read_a == 0)
abort();
printf("read_a = %d, read_b = %d\n", read_a, read_b);
exit(EXIT_SUCCESS);
}
被执行频率高的函数 fast_path 使用编译级的内存屏障代替 mfence, 被执行频率低的函数 slow_path 使用 membarrier 代替 mfence, membarrier (MEMBARRIER_CMD_GLOBAL) 被调用时会发送一个 inter-processor interrupt 给所有处理器, 使它们执行一个内存屏障保证未被执行的存储操作执行完毕 (即使 fast_path 中发生了out-of-order), 虽然 membarrier 调用的开销高, 但被调用的频率低, 相当于将 fast_path 的成本转移到了 slow_path
userspace-rcu 应用场景中, 读者进入 RCU 临界区是经常发生的, 而对 RCU 保护对象的更改可能不经常发生, 因此 rcu_read_lock() 调用内存屏障产生的开销都被浪费了, membarrier 将读者 (执行频率高) 的成本转移到写者 (执行频率低)
static inline __attribute__((always_inline))
int membarrier(int cmd, unsigned int flags, int cpu_id)
{
return syscall(__NR_membarrier, cmd, flags, cpu_id);
}
#define membarrier_master() membarrier(MEMBARRIER_CMD_PRIVATE_EXPEDITED, 0, 0)
#define membarrier_slave() barrier()
#define membarrier_register() membarrier(MEMBARRIER_CMD_REGISTER_PRIVATE_EXPEDITED, 0, 0)
2.2 实用函数
RMW(Read-Modifiy-Write) 可能是非原子的, 使用 volatile 关键字使变量不被加载到寄存器, 在 load 前和 store 后使用编译级内存屏障, 但并不能防止 CPU 的重新排序 (reordering), 合并 (merging) 或重新获取 (refetching)
#define access_once(x) (*(__volatile__ __typeof__(x) *)&(x))
#define load_shared(x) ({ barrier(); access_once(x); })
#define store_shared(x, v) ({ access_once(x) = (v); barrier(); })
在 spin-wait (busy-wait) 循环中使用 pause 指令可以提升性能
/* improves the performance of spin-wait loops */
#define PAUSE() __asm__ __volatile__ ("rep; nop":::"memory")
/* example: */
for (i = 0; i < RCU_WAIT_ATTEMPTS; ++i) {
if (load_shared(node->state) & RCU_WAIT_TEARDOWN)
break;
PAUSE();
}
统计时钟周期
/* counts clock cycles */
static inline __attribute__((always_inline))
uint64_t get_cycles()
{
unsigned int edx, eax;
__asm__ __volatile__ ("rdtsc" : "=a" (eax), "=d" (edx));
return (uint64_t)eax | ((uint64_t)edx) << 32;
}
2.3 用户态实现
2.3.1 grace period
linux 内核中的 gp 是从写者调用 call_rcu 开始, 在所有 CPU 的 Quiescent State 标志位改变后结束, userspace rcu 也做了类似的实现:
一个进程保存一个 gp 数据结构
typedef struct rcu_gp {
/*
* global grace period counter,
* written to only by writer with mutex taken,
* read by writer and readers.
*/
unsigned long ctr;
int32_t futex;
} rcu_gp;
wait_gp() 调用 futex 等待直到 gp 的 futex 不为 -1
/* synchronize_rcu() waiting single thread */
static void wait_gp(void)
{
membarrier_master();
pthread_mutex_unlock(&rcu_registry_lock);
if (load_shared(gp.futex) != -1) {
pthread_mutex_lock(&rcu_registry_lock);
return;
}
while (futex(&gp.futex, FUTEX_WAIT, -1, NULL, NULL, 0)) {
/* EWOULDBLOCK: the value pointed to by uaddr was not equal to the
* expected value val at the time of the call
*/
if (errno == EWOULDBLOCK) {
pthread_mutex_lock(&rcu_registry_lock);
return;
}
}
}
wake_up_gp() 当 gp 的 futex 为-1时将其置为0, 并唤醒最多一个 waiter
static inline void wake_up_gp(rcu_gp *gp)
{
if (unlikely(load_shared(gp->futex) == -1)) {
store_shared(gp->futex, 0);
futex(&gp->futex, FUTEX_WAKE, 1, NULL, NULL, 0);
}
}
2.3.2 读者
读者的数据结构 rcu_reader 是 tls(thread local storage), 可以使用 __thread 或者 pthread_key_create() 实现
typedef struct rcu_reader {
/* data used by reader and synchronize_rcu() */
unsigned long ctr;
char need_mb;
pthread_t tid;
/* reader registered flag, for internal checks */
unsigned int registered:1;
struct reader_list *list;
} rcu_reader;
typedef struct reader_list {
struct reader_list *next, *prev;
rcu_reader *node;
} reader_list;
读者的三种状态根据读者的 ctr(uint64) 来判断: inactive(低32位全为0), active current(低32位不全为0, 第33位等于 gp ctr 的第33位), active old(其他情况)
写者在 synchronize_rcu() 时会调用 wait_for_readers() 来等待input_readers 里没有 active old 状态的读者, 并将 active current 的移入到 cur_snap_reader 中, 将 inactive 的移入到 qs_readers 中
当循环判断的次数过多时就调用 wait_gp(), 等待读者结束时 rcu_read_unlock() 中调用 wake_up_gp() 来唤醒
static void wait_for_readers(reader_list *input_readers, reader_list *cur_snap_readers, reader_list *qs_readers)
{
unsigned int wait_loops = 0;
while (1) {
wait_loops++;
if (wait_loops >= RCU_QS_ACTIVE_ATTEMPTS) {
add_and_fetch(&gp.futex, -1);
membarrier_master();
}
reader_list *it = input_readers;
while (it != NULL) {
if (it->node != NULL) {
enum rcu_reader_state state = reader_state(&gp, it->node);
switch (state) {
case RCU_READER_ACTIVE_CURRENT:
if (cur_snap_readers) {
reader_move(it, cur_snap_readers);
break;
}
case RCU_READER_INACTIVE:
reader_move(it, qs_readers);
break;
case RCU_READER_ACTIVE_OLD:
break;
}
}
it = it->next;
if (it == input_readers) break;
}
/* if empty */
if (input_readers->next = input_readers) {
if (wait_loops >= RCU_QS_ACTIVE_ATTEMPTS) {
membarrier_master();
store_shared(gp.futex, 0);
}
break;
} else { /* exists old active readers */
if (wait_loops >= RCU_QS_ACTIVE_ATTEMPTS) {
wait_gp();
} else {
pthread_mutex_unlock(&rcu_registry_lock);
PAUSE();
pthread_mutex_lock(&rcu_registry_lock);
}
}
}
}
2.3.3 primitives
下面是5个原语的用户态大致实现:
内核中非抢占式 RCU 的 rcu_read_lock() 和 rcu_read_unlock() 只需要将抢占关闭/打开, 而用户态的实现中则需要如下操作:
读者进入时, 当读者为 inactive, 将读者置为 active current
void rcu_read_lock(void)
{
unsigned long tmp;
barrier();
tmp = tls_access_reader()->ctr;
/* if reader.ctr low 32-bits is 0 */
if (likely(!(tmp & RCU_GP_CTR_NEST_MASK))) {
store_shared(tls_access_reader()->ctr, load_shared(gp.ctr));
membarrier_slave();
} else {
store_shared(tls_access_reader()->ctr, tmp + 1);
}
}
读者退出时, 当读者不为 inactive, 将读者置为 inactive, 然后唤醒 gp
void rcu_read_unlock(void)
{
unsigned long tmp;
tmp = tls_access_reader()->ctr;
/* if reader.ctr low 32-bits equals to 1 */
if (likely((tmp & RCU_GP_CTR_NEST_MASK) == 1)) {
membarrier_slave();
store_shared(tls_access_reader()->ctr, tmp - 1);
membarrier_slave();
wake_up_gp(&gp);
} else {
store_shared(tls_access_reader()->ctr, tmp - 1);
}
barrier();
}
写者更新数据:
#define rcu_assgin_pointer(p, v) \
do { \
__typeof__(p) ____pv = (v); \
if (!__builtin_constant_p(v) || ((v) != NULL)) \
smp_mb(); \
store_shared(p, ____pv); \
} while (0) \
读者订阅数据: 其中使用到了 consume 内存序, 当前线程依赖于该值的变量的读写不会被重排到 load 前, 其他线程对数据依赖变量的写入可被当前线程可见: "所有异于 DEC Alpha 的主流 CPU 上,依赖顺序是自动的,无需为此同步模式产生附加的 CPU 指令,只有某些编译器优化收益受影响(例如,编译器被禁止牵涉到依赖链的对象上的推测性加载)。" — memory order
/* use p + 0 to get rid of ther const-ness */
#define rcu_dereference(p) __extension__ ({ \
__typeof__(p + 0) ____p1; \
__atomic_load(&(p), &____p1, __ATOMIC_CONSUME); \
(____p1); \
}) \
写者同步/异步等待所有 CPU 对旧数据的使用完成:
先调用一次 wait_for_readers() 来等待input_readers 里没有 active old 状态的读者, 并将 active current 的移入到 cur_snap_reader 中, 将 inactive 的移入到 qs_readers 中, 目的是保证上上个 gp 里没有读者, 且将上个 gp 里的读者放入 cur_snap_reader
然后将 gp ctr 的第33位取反
再调用一次 wait_for_readers() 等待 cur_snap_reader 里的读者离开上一个 gp
void synchronize_rcu(void)
{
/* current snapshot readers */
reader_list cur_snap_readers = { .next = &cur_snap_readers, .prev = &cur_snap_readers };
/* quiescent readers */
reader_list qs_readers = { .next = &qs_readers, .prev = &qs_readers };
wait_node wait = { .state = RCU_WAIT_WAITING };
wait_queue waiters = { NULL };
if (wait_queue_push(&gp_waiters, &wait) != 0) {
/* not first in queue: will be awakened by another thread */
adaptative_busy_wait(&wait);
smp_mb();
return;
}
wait.state = RCU_WAIT_RUNNING;
pthread_mutex_lock(&rcu_gp_lock);
wait_queue_move(&gp_waiters, &waiters);
pthread_mutex_lock(&rcu_registry_lock);
if (registry_reader_list.next == ®istry_reader_list)
goto out;
membarrier_master();
wait_for_readers(®istry_reader_list, &cur_snap_readers, &qs_readers);
/* enforce compiler-order of load reader.ctr before store to gp.ctr */
barrier();
store_shared(gp.ctr, gp.ctr ^ RCU_GP_CTR_PHASE);
/* enforce compiler-order of store to gp.ctr before load reader.ctr */
barrier();
wait_for_readers(&cur_snap_readers, NULL, &qs_readers);
/* put quiescent readers back into reader */
if (qs_readers.next != &qs_readers) {
reader_splice(&qs_readers, ®istry_reader_list);
}
membarrier_master();
out:
pthread_mutex_unlock(&rcu_registry_lock);
pthread_mutex_unlock(&rcu_gp_lock);
wait_node *it = waiters.head;
while (it != NULL) {
if (!(it->state & RCU_WAIT_RUNNING))
adaptative_wake_up(it);
it = it->next;
}
}