c/c++ 中的协程
1 什么是协程
Conway Melvin E 1963的文章《Design of a Separable Transition-Diagram Compiler》提出协程是可以挂起 (suspend) 和恢复 (resume) 的子例程 (subroutine), 为了实现这一点需要保存上下文 (context)
如下图 foo 和 bar 两个协程能多次的挂起和恢复, 每次恢复都恢复到上次挂起时的下条语句位置:
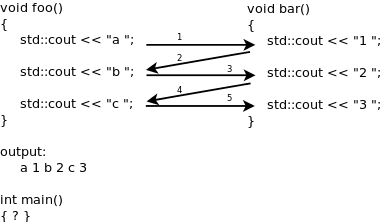
从控制流 (control flow) 的角度来说是一种语言层面 (language-level) 的控制流, 进程和线程中的逻辑控制流是由操作系统内核调度的, 而协程则是在语言层由程序员编写
下面我们就对比一下进程, 线程和协程
2 进程, 线程和协程
本文中提到的线程一般指的是 linux 2.6 后 glibc 中的 NPTL (Native POSIX Threads Library) 实现的线程, 一个用户态线程 posix thread 对应一个内核态轻量级进程 light-weight process
操作系统用 task_struct 这个结构体来描述一个进程或线程 (轻量级进程)
task_struct 有两个 id, pid 和 tgid, 类型均为 pid_t (x86_64 下为 int)
- pid 可通过 syscall(SYS_gettid) 获取
- tgid 可通过 getpid(2) 获取, 意为 thread group id, 即同一进程下的不同线程有不同的 pid 和相同的 tgid
- clone(2) 中 flags 如设为 CLONE_THREAD, 意为创建线程 (轻量级进程), 创建出来的线程的 tgid 和调用这个函数的进程的 tgid 一致
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ...
/* pid_t *ptid, void *newtls, pid_t *ctid */ );
同一线程组 (进程) 下的线程共享虚拟内存 (virtual address space), 文件描述符表 (table of file descriptors) 和信号处理表 (table of signal handlers)
信号处理是 process-wide 的, 即对整个线程组产生影响, 但每个线程可以有自己的 signal mask, 信号可以通过 kill(2) 或 tgkill(2) 发送给进程或者线程 (a signal may be process-directed or thread-directed)
2.1 进程和线程的上下文
进程的上下文包括内存空间和寄存器, 包括数据寄存器, 条件码, 栈指针, pc, 文件描述符表, brk 指针等等, 切换进程就会导致进程上下文的切换, 如 CR3 寄存器保存着当前进程页目录的物理地址, 切换进程就会改变 CR3 的值
如图所示为一个进程的内存空间
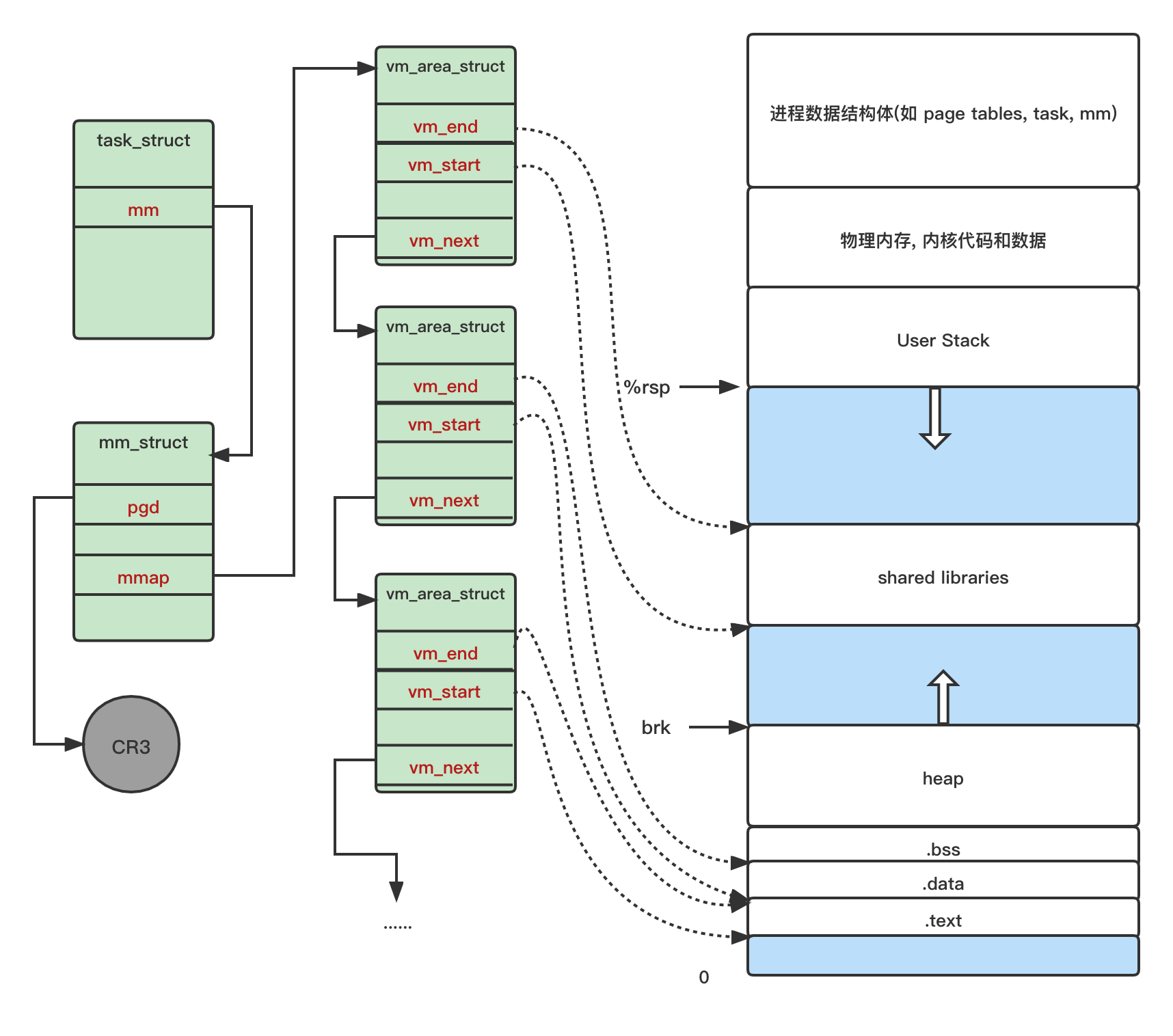
而线程作为轻量级进程, 由于共享同一线程组的部分数据, 上下文比进程小, 进程的 create 和 reap 需要约 20k cycles, 线程的 create 和 reap 只需要 10k cycles, 上下文切换时线程的开销也更小
线程有自己的栈, 有自己独有的数据 (thread-local storage) c/c++ 中通过 __thread 关键字修饰, tls 只能是 POD (plain old data) 的, 如每个线程都有属于它自己的局部 errno, tls 为段寄存器 FS/GS 指向的一块内存, 由 clone(2) 中的 newtls 参数传给 FS/GS, 此外还有线程特定数据 (thread-specific data)
2.2 协程的上下文
协程的上下文由具体实现决定, 一般都远小于线程的上下文, context 也称为 continuation 意为一个函数剩下的部分
3 协程的分类
协程可以根据 stackfulness 分为有栈和无栈, 根据上下文是否可以作为参数传递分为 first-class continuation 或非 first-class continuation, 根据协程间的关系分为对称和非对称的
- stackful
- resume 协程时将栈指针指向 user 在堆上运行时创建的一块内存, 可能会破坏 return stack buffer 跳转预测
- stackless
- 不将栈指针指向堆上创建的内存
对于阻塞调用:
- stackful 改变阻塞调用的行为, 让内核调度改为线程内调度
- stackless 将剩余部分定义为一个函数, 注册这个函数为回调函数, 当前函数返回
4 setjmp and longjmp
c/c++ 中自带的 setjmp 和 longjmp 就可以看做是一种协程, 其上下文为 8 个寄存器的值, 存在 __jmp_buf 这个结构体中
/* callee saved */
struct __jmp_buf {
unsigned long __rbx;
unsigned long __rsp; /* post-return */
unsigned long __rbp;
unsigned long __r12;
unsigned long __r13;
unsigned long __r14;
unsigned long __r15;
unsigned long __rip; /* return address */
};
setjmp 将上下文保存在 __jmp_buf 中
kernel_setjmp:
pop %rsi # Return address, and adjust the stack
xorl %eax,%eax # Return value
movq %rbx,(%rdi)
movq %rsp,8(%rdi) # Post-return %rsp!
push %rsi # Make the call/return stack happy
movq %rbp,16(%rdi)
movq %r12,24(%rdi)
movq %r13,32(%rdi)
movq %r14,40(%rdi)
movq %r15,48(%rdi)
movq %rsi,56(%rdi) # Return address
ret
longjmp 将 __jmp_buf 中的值恢复到寄存器
kernel_longjmp:
movl %esi,%eax # Return value (int)
movq (%rdi),%rbx
movq 8(%rdi),%rsp
movq 16(%rdi),%rbp
movq 24(%rdi),%r12
movq 32(%rdi),%r13
movq 40(%rdi),%r14
movq 48(%rdi),%r15
jmp *56(%rdi)
5 达夫设备
达夫设备源自 Duff 尝试使用 switch 和循环对下面这段代码做 unrolling 优化
https://swtch.com/duffs-device/td-1983.txt
send(to, from, count)
register short *to, *from;
register count;
{
do
*to = *from++;
while(--count>0);
}
使用循环展开后:
send(to, from, count)
register short *to, *from;
register count;
{
register n=(count+7)/8;
switch(count%8){
case 0: do{ *to = *from++;
case 7: *to = *from++;
case 6: *to = *from++;
case 5: *to = *from++;
case 4: *to = *from++;
case 3: *to = *from++;
case 2: *to = *from++;
case 1: *to = *from++;
}while(--n>0);
}
}
PuTTY 的作者 Simon Tatham 根据达夫设备的特性实现了一种无栈协程
int function(void) {
static int i, state = 0;
switch (state) {
case 0: /* start of function */
for (i = 0; i < 10; i++) {
state = 1; /* so we will come back to "case 1" */
return i;
case 1:; /* resume control straight after the return */
}
}
}
这个协程的 context 为放在 .bss 上的两个 int, 每次进入这个函数时都会根据这两个 int 跳转到不同的语句, 由于使用到了多个线程可访问到的静态数据, 所以这个函数是不可重入的
6 libco
libco 是微信开源的 c++ 协程库, 属于有栈非对称的协程, 其上下文为 14 个寄存器的值和一块运行时在堆上创建的栈, 寄存器的值保存在一个叫 regs 的数组中:
| regs[0]: r15 | |
| regs[1]: r14 | |
| regs[2]: r13 | |
| regs[3]: r12 | |
| regs[4]: r9 | |
| regs[5]: r8 | |
| regs[6]: rbp | |
| regs[7]: rdi | first argument |
| regs[8]: rsi | second argument |
| regs[9]: ret | ret func addr 0(%rsp) |
| regs[10]: rdx | |
| regs[11]: rcx | |
| regs[12]: rbx | |
| regs[13]: rsp |
rsp 指向的是返回的地址(rax), 即上下文切换语句的下一行的汇编指令的第一条
一个协程对应着在堆上创建的一个栈, 也可以使用共享栈模式, 即多个协程共享同一个栈, 但任意时刻只有一个协程在真正执行, 共享栈需要保存和恢复, 相当于用时间换空间
协程上下文的切换在 libco 中使用汇编实现
主协程一直不断地从名为 active_list 的队列中取出就绪的协程恢复, 时间轮中的超时事件会被加到 active_list 中, epoll_wait 返回的事件 events[i].data.ptr 会被加到 active_list 中, 此外也可以主动将一些想要恢复的协程加到 active_list 中, 如官方的生产者消费者例子中
我们可以对比看下生产者消费者问题分别用进/线程和协程如何解决:
- 进程: 通过 futex 同步, 映射到同一个物理内存地址的 futex 变量
- 线程: 通过 futex 同步, 共享虚拟内存空间中的 futex 变量
- 协程: 通过用户定义的变量同步
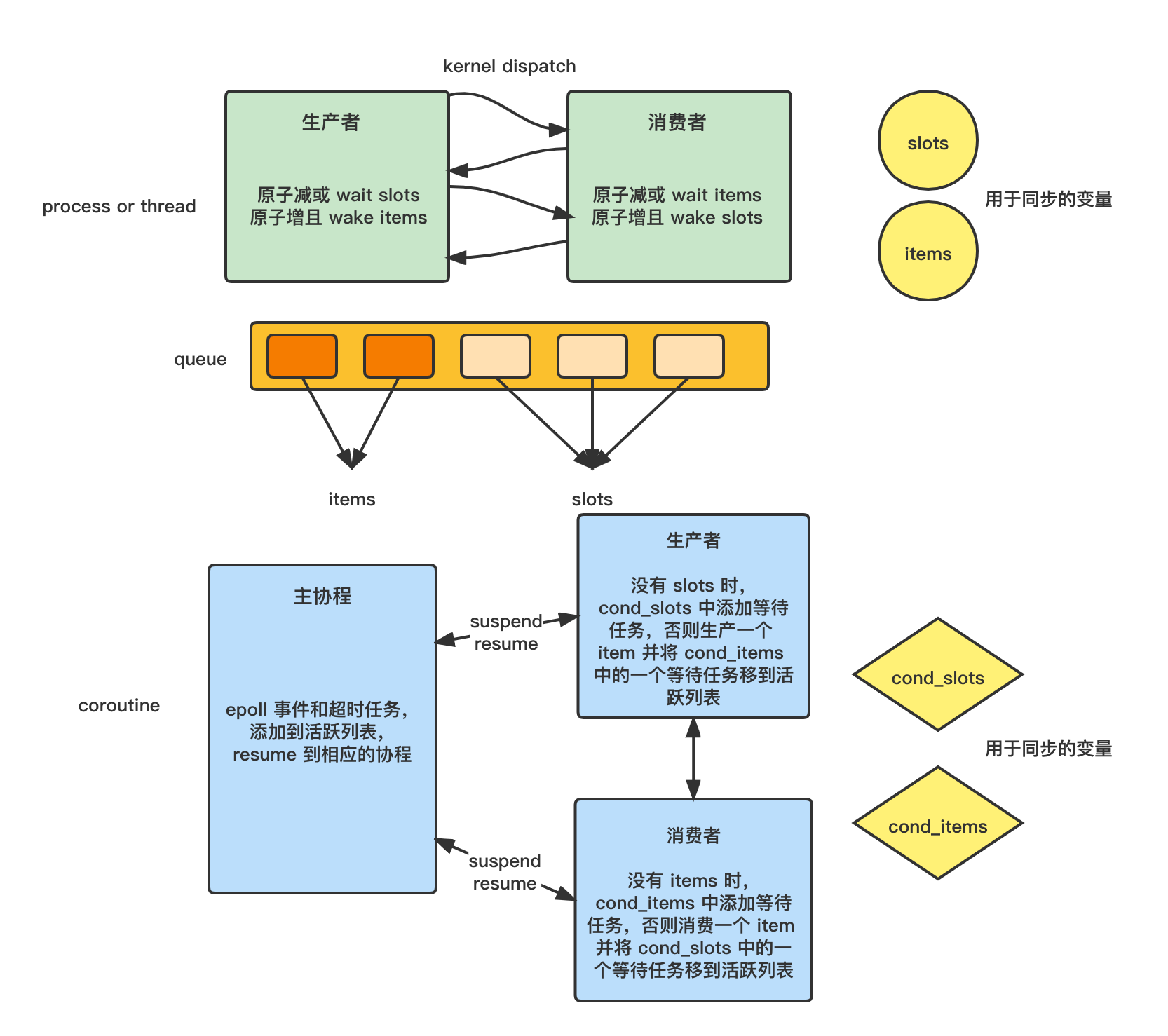
7 ucontext
linux 也提供 ucontext 这个结构体用来便于我们来保存协程上下文, 同时提供了切换上下文的函数, 而不用像 libco 那样自己编写汇编:
#include <ucontext.h> void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...); int swapcontext(ucontext_t *oucp, ucontext_t *ucp); int getcontext(ucontext_t *ucp); int setcontext(const ucontext_t *ucp);
上下文比 libco 的多了 sigmask 和浮点数
/* Userlevel context. */
typedef struct ucontext_t
{
unsigned long int __ctx(uc_flags);
struct ucontext_t *uc_link;
stack_t uc_stack;
mcontext_t uc_mcontext;
sigset_t uc_sigmask;
struct _libc_fpstate __fpregs_mem;
unsigned long int __ssp[4];
} ucontext_t;
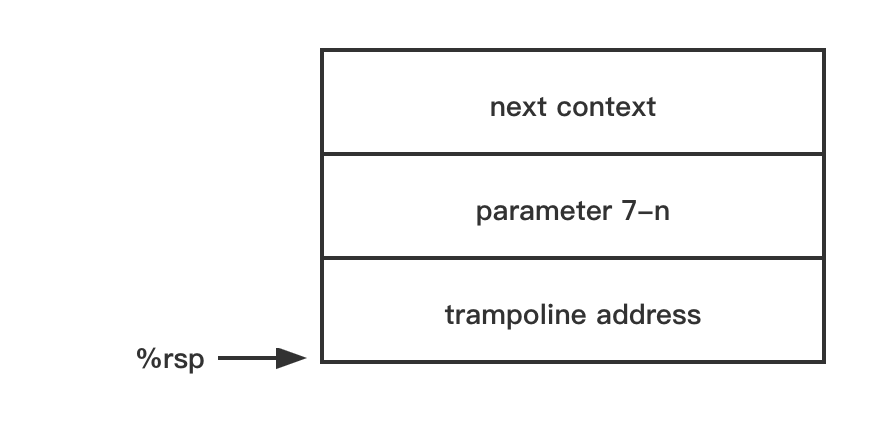
ucontext 也是有栈协程, 协程的栈如下图:
8 c++ 20 coroutine ts
This allows for sequential code that executes asynchronously (e.g. to handle non-blocking I/O without explicit callbacks), and also supports algorithms on lazy-computed infinite sequences and other uses.
cppreference coroutine 页面上介绍协程的用处是可以编写异步执行的顺序代码, 如减少异步事件驱动中的显式回调函数注册, c++ 20 标准库中的使用的是无栈协程, 主要有三个关键字:
- 使用 co_await 来 suspend 直到 resumed
- 使用 co_yield 来 suspend 并返回一个值
- 使用 co_return 来完成并返回一个值
我们通常定义协程返回对象和可等待体
8.1 返回对象
协程的返回对象中通常需要定义一个 promise_type 结构体, promise_type 中的 get_return_object() 函数用于创建返回对象, initial_suspend() 决定协程创建后是否马上运行, final_suspend 决定协程已处理完毕释放前是否要挂起, yield_value() 在 co_yield 时被调用, return_value()/return_void() 在 co_return 时被调用, unhandled_exception() 来处理异常
template<class T>
struct ReturnObject {
struct promise_type {
T value_;
std::exception_ptr exception_;
ReturnObject get_return_object() {
return { .handler_ = std::coroutine_handler<promise_type>::from_promise(*this) };
}
std::suspend_nerver initial_suspend() { return {}; }
std::suspend_always final_suspend() { return {}; }
template<std::convertible_to<T> From>
std::suspend_always yield_value(From &&from) {
value_ = std::forward<From>(from);
return {};
}
void return_void() {}
void unhandled_exception() { exception_ = std::current_exception(); }
};
std::coroutine_handler<promise_type> handler_;
};
8.2 可等待体
可等待体是实现了 await_ready(), await_suspend(), await_resume() 这几个函数的类, 如 std::suspend_never 和 std::suspend_always 就是官方实现的两个可等待体
struct suspend_never {
constexpr bool await_ready() const noexcept { return true; }
constexpr void await_suspend(std::coroutine_handle<>) const noexcept {}
constexpr void await_resume() const noexcept {}
};
struct suspend_always {
constexpr bool await_ready() const noexcept { return false; }
constexpr void await_suspend(std::coroutine_handle<>) const noexcept {}
constexpr void await_resume() const noexcept {}
};
当使用 co_await 时调用 await_ready() 判断是否要挂起当前线程, 然后会调用 await_suspend() 用于挂起协程, 协程被恢复时调用 await_resume()
template<class PromiseType>
struct Awaitable {
PromiseType *promise_;
bool await_ready() { return false; }
bool await_suspend(std::coroutine_handle<PromiseType> h) {
promise_ = &h.promise();
return false;
}
PromiseType *await_resume() { return promise_; }
};
8.3 echo server
我们可以使用 c++ 20 协程来实现一个回显服务器, Accept() 函数负责接受远程的 tcp 连接, Echo() 函数负责对已建立连接的 socket 进行读写
如图所示, 在 Accept() 函数中使用 co_await 关键字让出 cpu 时间片并将函数的剩下部分包装成回调函数, 当这个异步 accept 成功建立 tcp 连接后恢复这个函数执行下一条语句
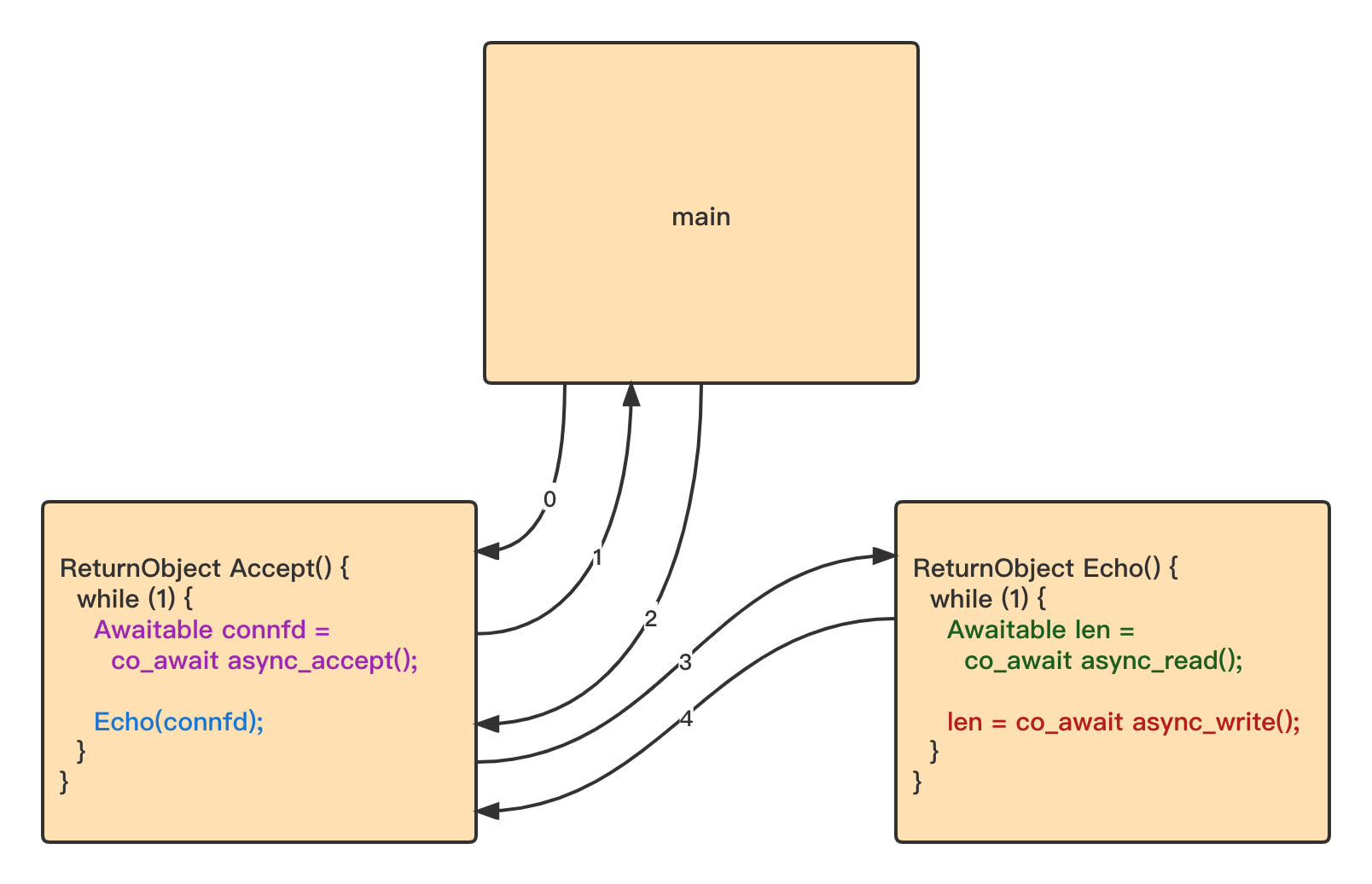
9 asio 中的三种协程
asio 中有过三种协程, 基于达夫设备的简单的无栈协程, 基于 boost coroutine2 的有栈协程, 而 boost coroutine2 是基于 ucontext (或 boost 自己对 ucontext 的另外的实现), 基于 c++ 20 标准库协程的无栈协程
| 3 asio coroutines | 原理 | stackfulness |
|---|---|---|
| Stackless Coroutines | 类似于 Duff's Device 达夫设备 | stackless |
| Stackful Coroutines | boost.coroutine2 的包装 | stackful |
| Coroutines TS Support | c++20 标准库的包装 | stackless |
9.1 boost coroutine2
boost coroutine2 中有类似 ucontext 的实现, 名为 fcontext, 像 libco 一样也是基于汇编
Performance of context switch
| callcc()/continuation (fcontext_t) | callcc()/continuation (ucontext_t) | callcc()/continuation (Windows-Fiber) |
| 9 ns / 19 CPU cycles | 547 ns / 1130 CPU cycles | 49 ns / 98 CPU cycles |
| based on assembler | POSIX-platforms | Win |
9.2 stackless coroutines
asio 中有两种无栈协程, 其中不基于 c++ 20 的这种是像 PuTTY 那样简单的使用达夫设备
#define ASIO_CORO_REENTER(c) \
switch (::asio::detail::coroutine_ref _coro_value = c) \
case -1: if (_coro_value) \
{ \
goto terminate_coroutine; \
terminate_coroutine: \
_coro_value = -1; \
goto bail_out_of_coroutine; \
bail_out_of_coroutine: \
break; \
} \
else /* fall-through */ case 0:
#define ASIO_CORO_YIELD_IMPL(n) \
for (_coro_value = (n);;) \
if (_coro_value == 0) \
{ \
case (n): ; \
break; \
} \
else \
switch (_coro_value ? 0 : 1) \
for (;;) \
/* fall-through */ case -1: if (_coro_value) \
goto terminate_coroutine; \
else for (;;) \
/* fall-through */ case 1: if (_coro_value) \
goto bail_out_of_coroutine; \
else /* fall-through */ case 0:
#define ASIO_CORO_FORK_IMPL(n) \
for (_coro_value = -(n);; _coro_value = (n)) \
if (_coro_value == (n)) \
{ \
case -(n): ; \
break; \
} \
else
10 上下文对比
最后我们对比一下下面提到的几种协程(setjmp/longjmp, duff's device, libco, ucontext, c++20 coroutine, boost coroutine2) 的上下文
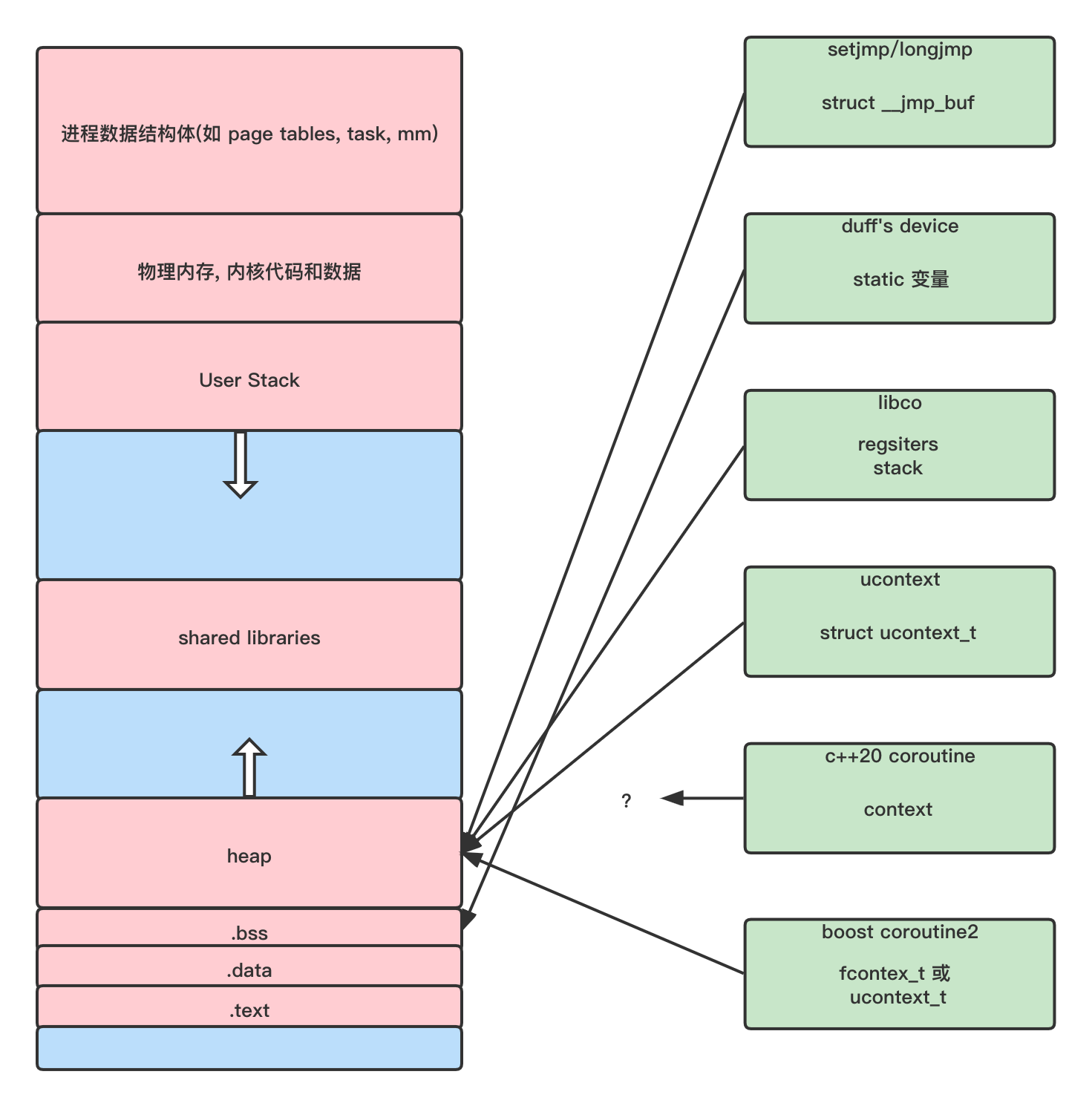
大部分的协程都将上下文保存到了堆上, 大小由 libco 的 128k 左右到几个 int 不等, 通常由实际应用场景决定, 如 libco 中没有浮点数寄存器而 ucontext 中有
11 conclusion
协程是在用户态的一种非抢占式的调度, 提供了相对于线程颗粒度更细的并发 (fine-grained concurrency), 提高单个线程的能力, 但只用单个线程无法利用多核的优势实现并行